
I have been in the business of book and journal composition for over 25 years. A lot has changed, but a lot hasn’t. In general, the production process, from authoring to publication has a lot of inefficiencies. There is “reverse engineering” at several points, but perhaps the process of checking and formatting of references is the most striking example. Let’s look at the whole process.
Authoring
Author guidelines
A prospective author’s first port of call for submitting to a journal is the “Author Guidelines” for the journal. To see this, just google a journal name at random and “author guidelines” off the top of your head, e.g. google
journal of chemical biology author guidelines
(I just made up the name, and I have never heard of the journal that google found so please don’t sue me!) You will come to this page. Have a quick scroll through to see what we put poor authors through. A scientist has just finished a research program and wants to publish it, but before going further is asked to read through this tedious document. In an age where we read fewer and fewer documents, this must be close to being classed as cruelty! So before the author writes their document, they need to ensure it conforms to the details in the guideline. And all the time they are aware that if their paper is rejected by this journal, they would have to start reading the guidelines for another journal!
References
Let’s look at a tiny part of the instructions, namely the references. The author is given examples for different types of references, e.g. books or journal articles, including the placement of punctuation, test style, e.g. bold and italic, etc. In case the author is using Thomson Reuters’ EndNote, they are given instructions on how to export the correct format for the journal from the program. In this case there are no instructions for authors using other programs such as Zotero, Mendeley, etc.
A quick word on reference managers
Reference managers are the powerful, modern equivalent of index cards, and take the drudgery out of keeping track of references to scholarly literature. Let’s take a quick look at one of these, the free and open source Zotero. Suppose I have found this PLOS paper on the web and I want to add it to my reference library:
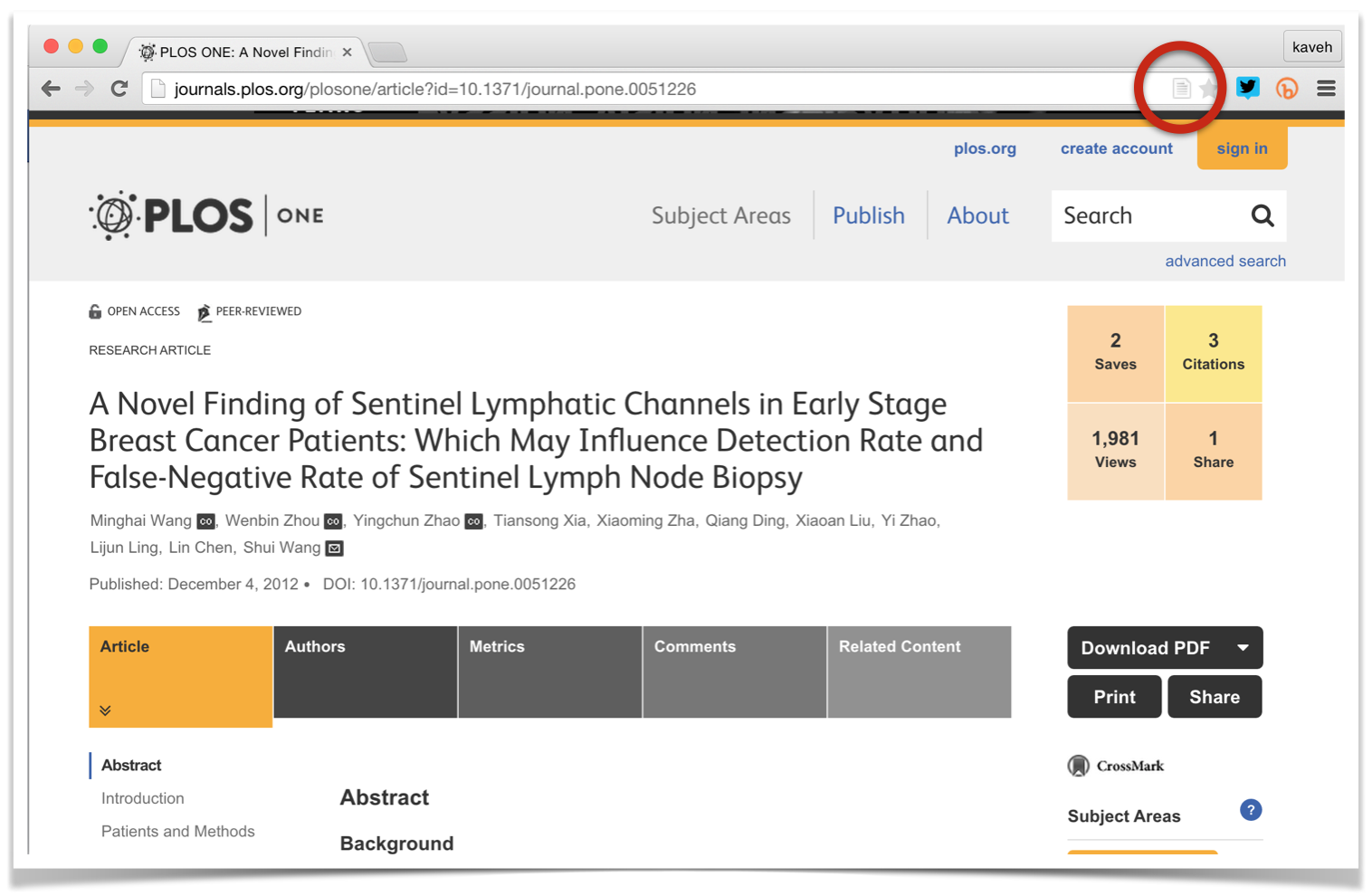
When the Zotero plugin is installed, any page that looks like a possible reference (even newspaper articles) shows a Zotero icon in the URL bar (circled in the figure). Clicking this icon silently scrapes the relevant data from the HTML, and saves the information in the database, so when the Zotero application is next opened, all the metadata referring to the page is visible:
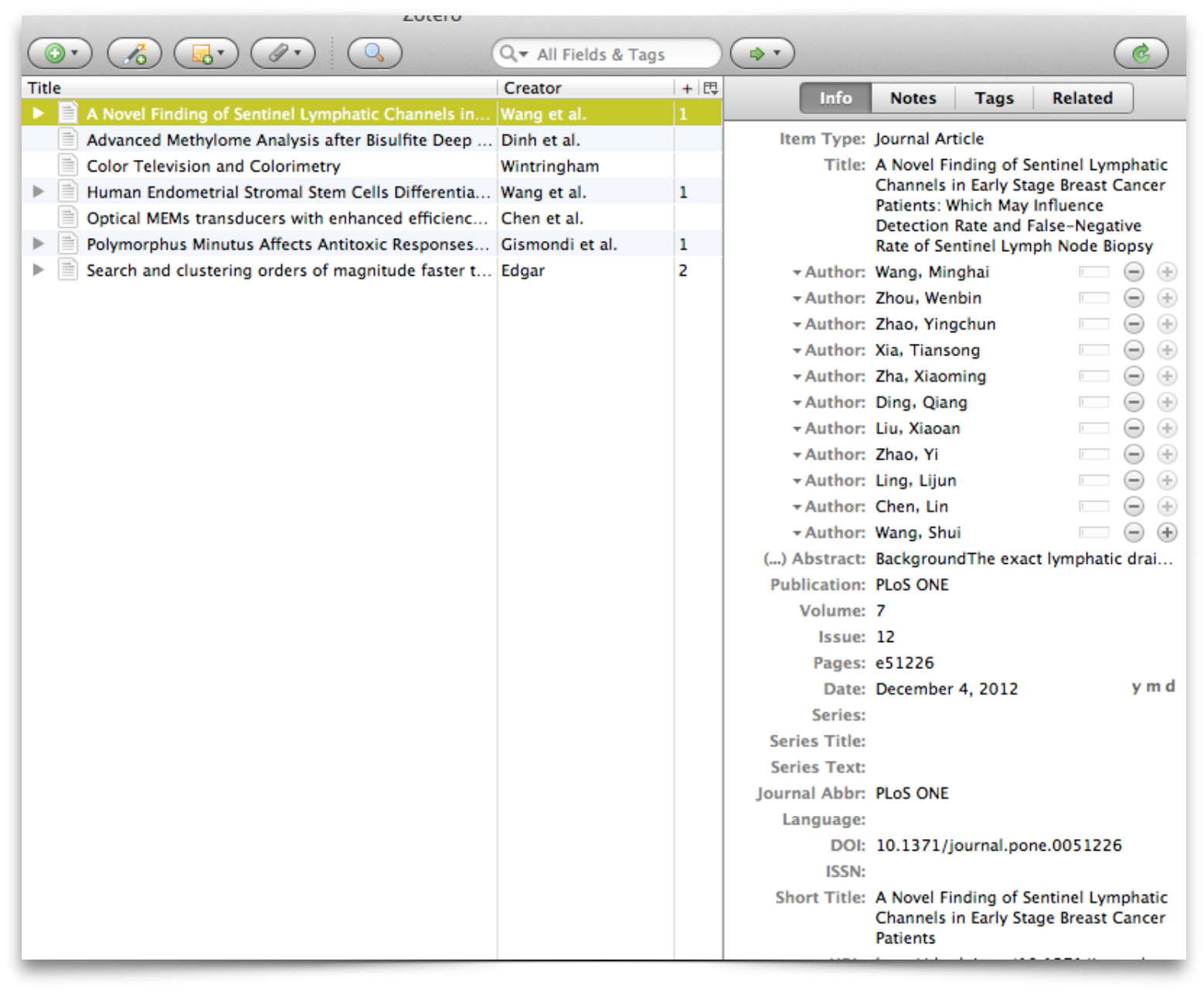 So with one click, every conceivable piece of relevant information regarding the page is saved to the Zotero database. But now the author has to transform this complete data into the final form requested by the journal, e.g. something like
So with one click, every conceivable piece of relevant information regarding the page is saved to the Zotero database. But now the author has to transform this complete data into the final form requested by the journal, e.g. something like
MacDonald, G. M., Steenhuis, J. J., and Barry, B. A. (1995) A difference Fourier transform infrared spectroscopic study of chlorophyll oxidation in hydroxylamine-treated photosystem II. J. Biol. Chem. 270, 8420–8428
This used to be a terrible chore as you can imagine – manually rewriting each reference in the required form. But the reference managers cottoned on to this and allowed the references to be output perfectly for any publishers. What a joy, so you simply click and rather like toothpaste out of a tube, the structured data is converted to the style required by the publication, and ready to print. Bingo.
The paper is submitted, the publisher is delighted that the style is just as prescribed, it is passed to peer review, and let’s assume it is accepted and passed to production. Invariably the production is outsourced to companies like mine who have offices in countries with (to be blunt) cheap labour.
The production process
The manuscript production process is effectively a “pipeline” of perhaps 20 stages that transform the author’s submission to the final “deliverables”, including stages such as
- Copy editing
- Figure preparation
- Embedding links
- XML preparation
- Proofreading
- Pagination
XML is now ubiquitous, at least for the “head and tail”, i.e. for prelims and abstract, and for references. Increasingly publishers specify “full” XML, i.e. of the whole content. And they (rightly) insist on an “XML-first” workflow, so the XML must be created first, and then PDF, Epub etc are generated from that XML. This ensures that the latter is the definitive source for all formats. There are several stages that are effectively reverse-engineering, but none more striking than the preparation of the references.
Preparing references
So, the author has prepared the manuscript, taking care that the references are exactly according to the journal style, aided by third party reference managers. And the author is a bit aggrieved that she has had to do the publisher’s work for them, but thinking that at least it has saved the publisher time in preparing the final manuscript. She couldn’t be more wrong!!
Back to the (commendable) XML-first requirement. So the first thing the supplier has to do is to prepare the XML for the file. Each reference has to be structured according to the publisher’s requirements, with page number, volume, etc tagged correctly. But the references in the manuscript have no structure – they’re just words and punctuation, with some text styling. Hang on – in the original reference manager (the toothpaste tube) all the data was beautifully saved, wasn’t it? Yes, it was. But that was all discarded when the toothpaste was squeezed out!
So, somehow we need to get back to the full data. And the standard way is to send a query for each reference to a service such as CrossRef, and hopefully get back the full data. If the author has done her job properly, then this is pretty reliable. If not, there will be some manual work to be done and decisions made by operators. Where there is doubt, a query will go back to the author. There are even very sophisticated third party commercial tools (e.g. Extyles and Merops) that help in this reverse-engineering, getting the data back with various degrees of accuracy.
OK, so we have got the data, and we now have a structured XML file and stuffed the toothpaste back into the tube. But now we need to send a proof to the author, with the references again in the journal style, including punctuation etc – time to squeeze that tube again! So for each journal, the supplier needs to write a filter to generate the final style. (There is also the freely available Citation Style Language now that does that squeezing.) And now it’s the author’s responsibility to check carefully and ensure there are no errors.
My company benefits from this reverse engineering, as do the companies selling the software. But there’s got to be a better way!
kaveh
February 12, 2018 at 8:30 am
Hi Guido
The “production” side of scholarly publications, i.e. typesetting, pagination, XML creation, etc. are almost always outsourced by publishers to offshore companies (like ours!). The details are not normally made public and in many cases the publishers are not themselves aware of the exact details of how the work is done. Our job is to take what the author has given and deliver the final files to be published. Each supplier will have their own method of producing the final files. Sorry there is not much more information on this, and thanks for your comment.
Regards
Kaveh